2월 3주차 스터디 발표 자료📖
3주차 기술면접 주제 중 첫번 째 주제입니다!
DB 인덱스 개념에 대해 정리하고자 합니다.
참고(10분 테코톡): https://www.youtube.com/watch?v=edpYzFgHbqs&t=329s
인덱스
- 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이며, where절을 통해 활용된다.
- 인덱스도 하나의 데이터베이스 객체이며, 저장 공간이 필요하다.
- Oracle, DB2 등에서는 스키마 객체로 MySQL, SQL Server 등에서는 테이블 내의 객체로 존재한다.
- 사용하는 목적?
대용량 데이터에서 원하는 데이터를 빠르게 조회(Select)하기 위해!
인덱스의 종류
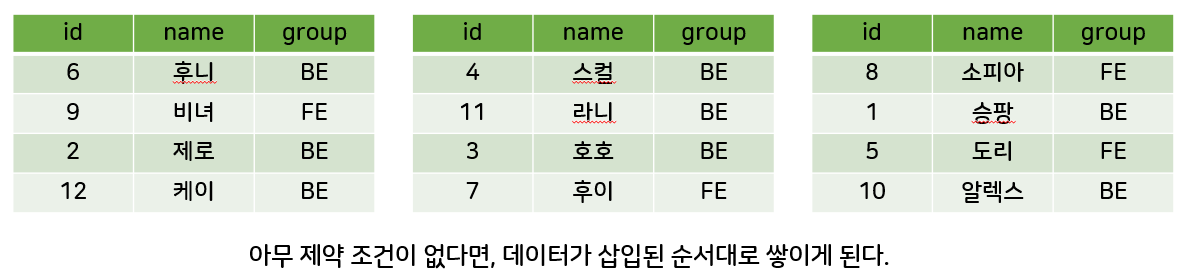
- 우리도 모르는 사이에 인덱스를 사용하고 있었다??
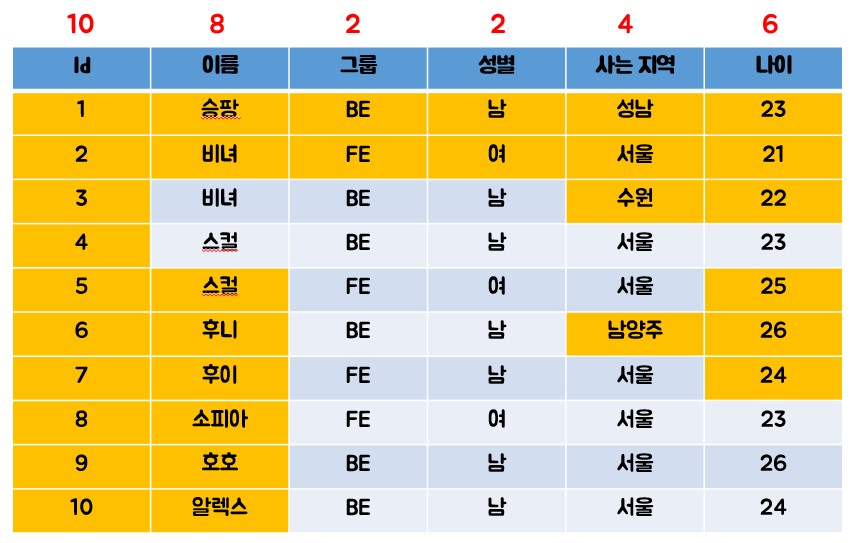
1 2 3 4 5 6
-- 2개의 인덱스가 존재함(자동 생성)! CREATE TABLE member ( id int primary key, name varchar(255), email varchar(255) unique );
Clustered Index
- 실제 데이터와 무리를 이룬 인덱스
- primary key를 생성하면 자동으로 클러스터링 인덱스가 생성된다.
- 클러스터링 인덱스를 적용하는 방법?
1 2 3 4 5
-- 방법 1 ALTER TABLE member ADD CONSTRAINT pk_id PRIMARY KEY (id); -- 방법 2 ALTER TABLE member MODIFY COLUMN id int NOT NULL; ALTER TABLE member ADD CONSTRAINT nuq_id UNIQUE (id);
- 클러스터링 인덱스의 생성 과정 및 데이터 탐색
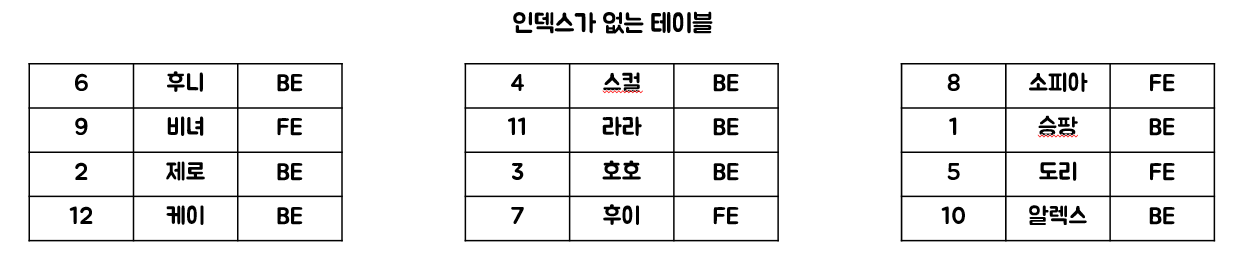
- 클러스터링 인덱스 적용 전
![cluster-before]()
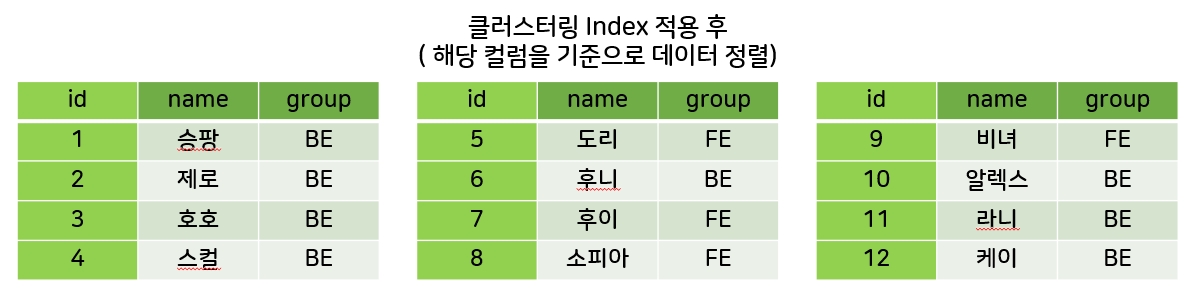
- 인덱스 적용 후 (id에 primary key 설정함)
![cluster-after]()
- 정렬된 데이터를 기준으로 루트페이지가 생성된다.
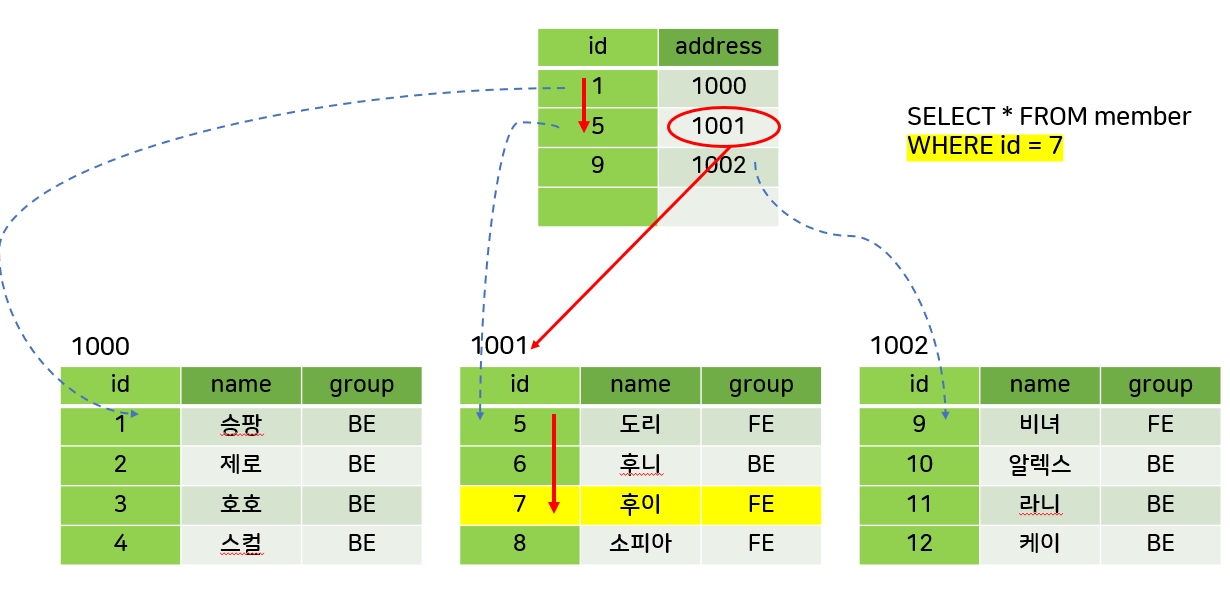
리프 페이지(데이터 페이지)는 실제 데이터가 저장되는 곳이다.![cluster-after2]()
- 클러스터링 인덱스 적용 전
- 클러스터링 인덱스의 특징
- 실제 데이터 자체가 정렬된다
- 테이블 당 1개만 존재 가능하다.
- 리프페이지가 데이터 페이지이다.
- primary key(우선 순위)와 unique + not null 제약 조건에서 자동 생성된다.
Non-Clustered Index
- 보조 인덱스, 세컨더리 인덱스라고도 불린다.
- 실제 데이터와 무리를 이루지 않은 인덱스
- unique 제약조건을 걸면 논 클러스터링 인덱스가 생성된다.
- 논 클러스터링 인덱스 적용하는 방법?
1 2 3 4 5 6
-- 방법 1 ALTER TABLE member ADD CONSTRAINT unq_name UNIQUE (name); -- 방법 2 CREATE TABLE UNIQUE INDEX unq_idx_name ON member (name); -- 방법 3 CREATE INDEX idx_name ON member (name);
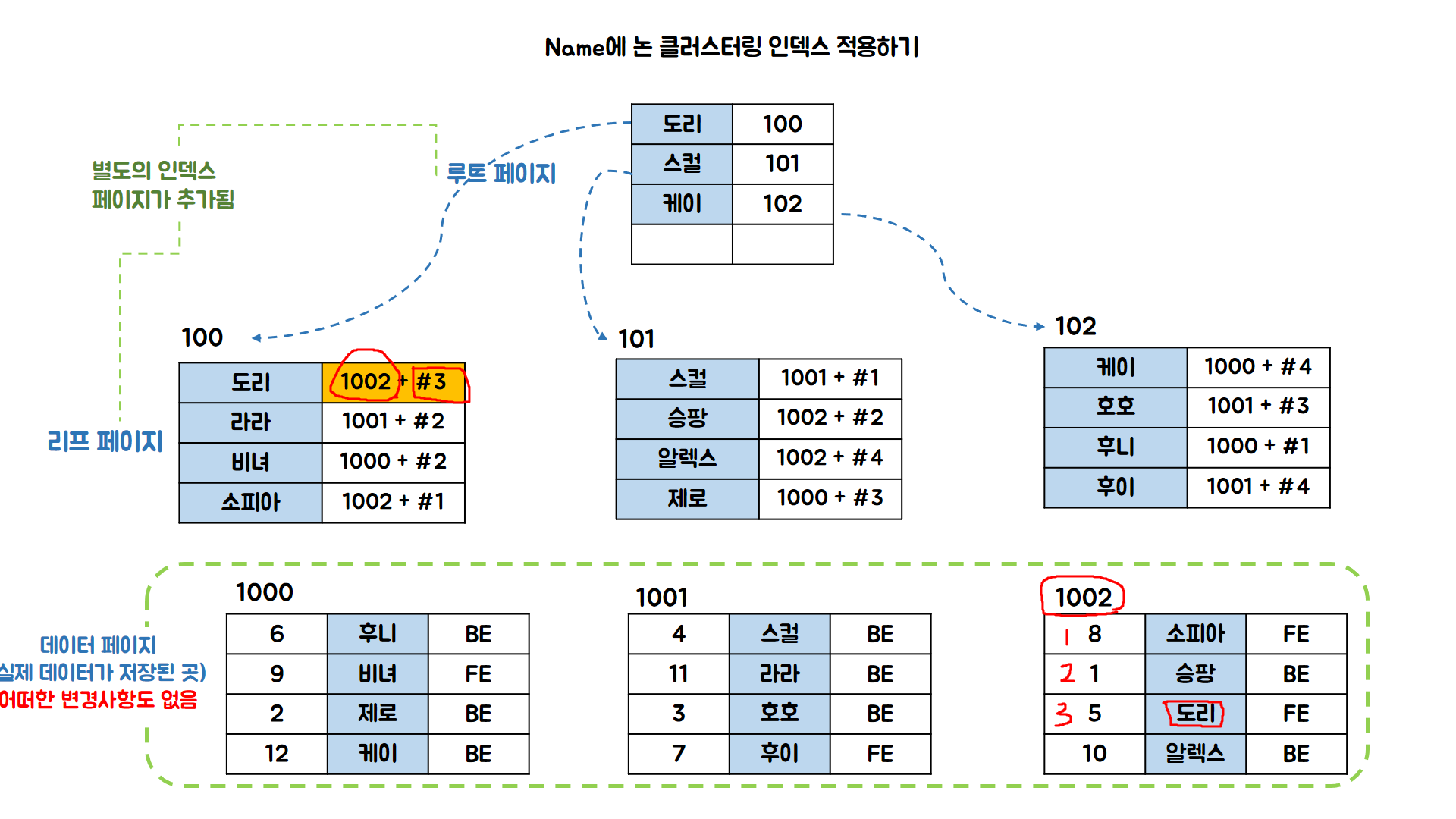
- 논 클러스터링 인덱스의 생성과정 및 데이터 탐색
- 논 클러스터링 인덱스 적용 전
![index before]()
- 논 클러스터링 인덱스 적용 후
![noncluster]()
- 정렬된 데이터를 기준으로 인덱스 페이지가 생성된다.
![noncluster-search]()
- 논 클러스터링 인덱스 적용 전
- 논 클러스터링 인덱스의 특징
- 실제 데이터 페이지는 그대로 존재 ( 변경사항 없음 )
- 별도의 인덱스 페이지가 생성된다. 따라서 추가 공간이 필요함
- 테이블당 여러 개가 존재할 수 있다.
- 리프 페이지에 실제 데이터 페이지 주소를 담고있다.
- unique 제약조건 적용시 자동으로 생성된다.
- 직접 index 생성 시, 논 클러스터링 인덱스가 생성된다.
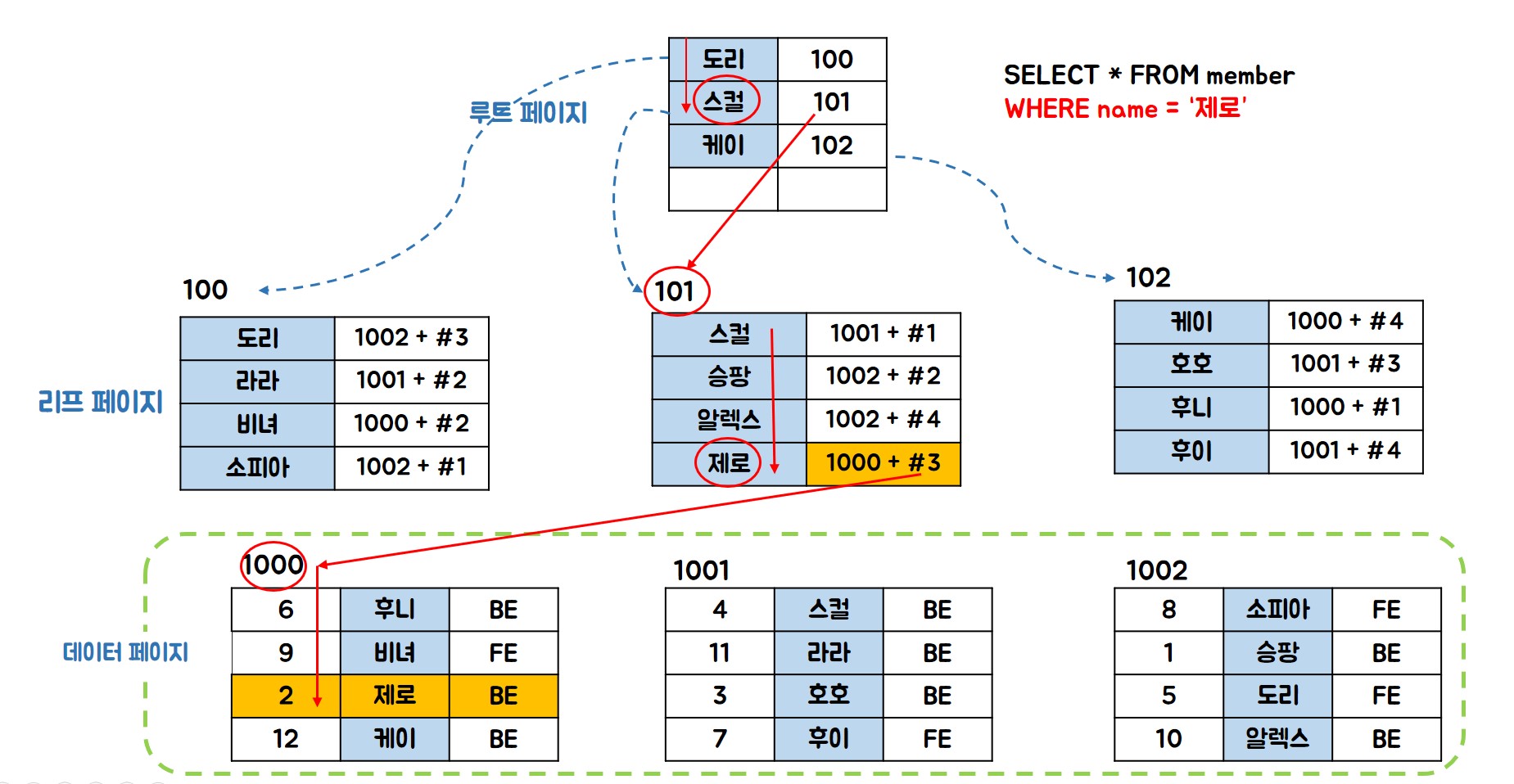
Clustered + Non-Clustered
- 논 클러스터링 리프 페이지에 실제 데이터 주소가 아닌 클러스터링 인덱스가 적용된 컬럼의 실제 값이
저장된다.
👉 즉, 클러스터링 인덱스가 id에 적용됬으면 id 값이 저장되고, 이름에 적용됬으면 이름이 저장됨.
![multi-index]()
인덱스 검색 알고리즘
- 페이지? 데이터가 저장되는 단위, MySQL 기준 16KB 정도
Full Table Scan
처음부터 끝까지 데이터를 순차적으로 전부 훑어본다.

위의 예시에선 ppp를 찾기위해 12번의 검색과정을 거침
- Full Table Scan은 언제 사용할까?
- 적용 가능한 인덱스가 없는 경우
- 인덱스 처리 범위가 넓은 경우
- 크기가 작은 테이블에 엑세스하는 경우
B-Tree (Balanced-Tree)
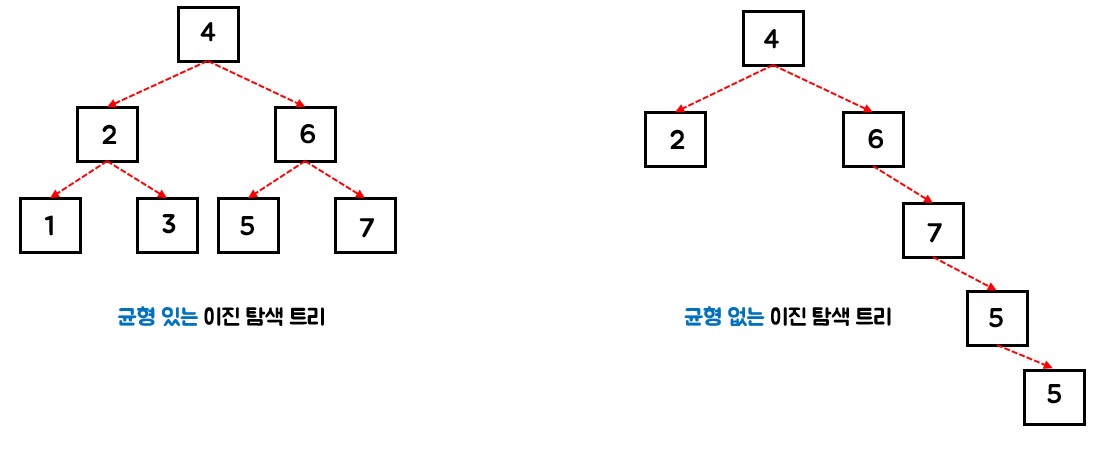
- 이진 탐색 트리?
균형 있는 이진 탐색의 경우 시간 복잡도는 O(log n)이지만, 균형 없는 이진 탐색 트리는 최악의 경우 O(n)의 시간복잡도가 발생한다.![이진 탐색]()
- B-Tree?
균형 없는 이진 트리의 단점을 해소하고자 나온 것이 B-Tree이다.- 트리의 높이가 같다.
- 자식 노드를 2개 이상 가질 수 있다.
- 기본 데이터 베이스의 인덱스 구조
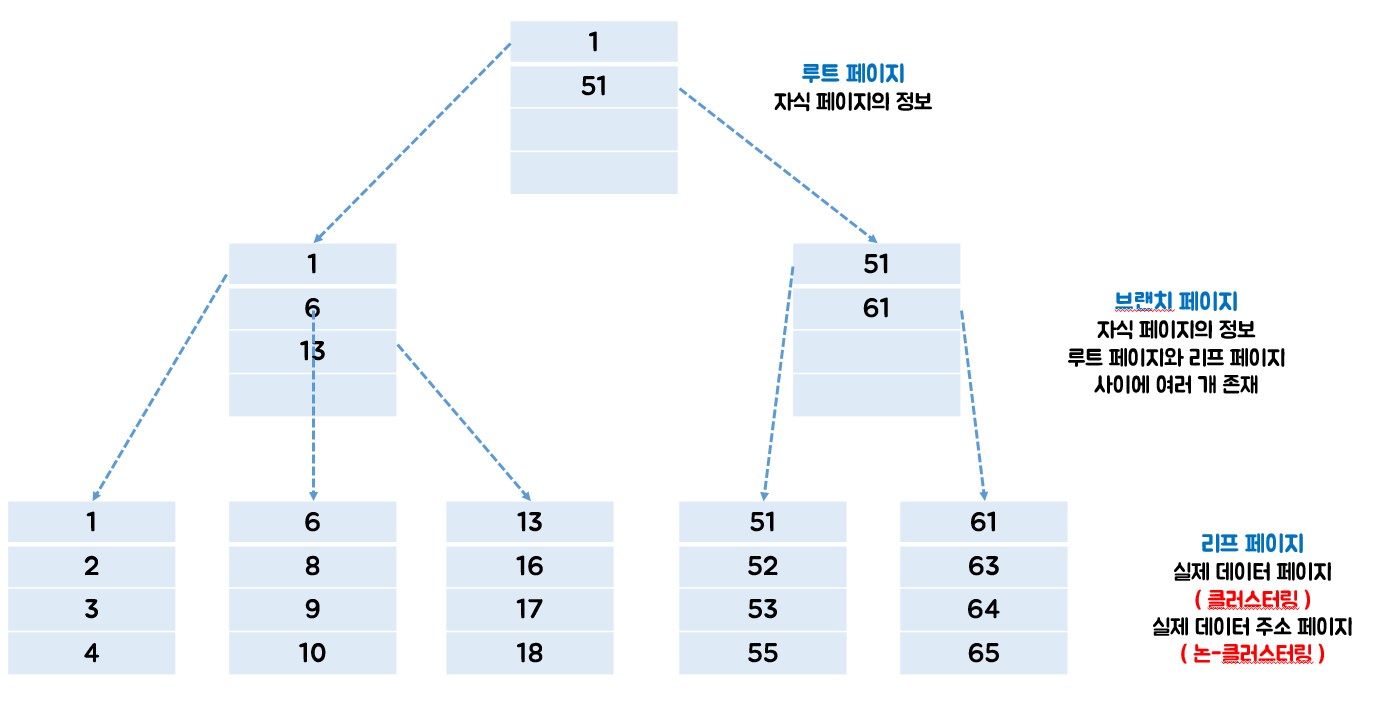
- B-Tree 구조
![구조]()
- B-Tree 탐색 과정
ppp를 찾기위해 6번의 검색과정을 거침. Full Table Scan 보다 효율적이다.![B-Tree 탐색과정]()
B-Tree의 Insert
인덱스를 통해 Select 성능이 개선된 것을 볼수있었다. Insert, Update, Delete도 마찬가지로 성능이
향상될까?
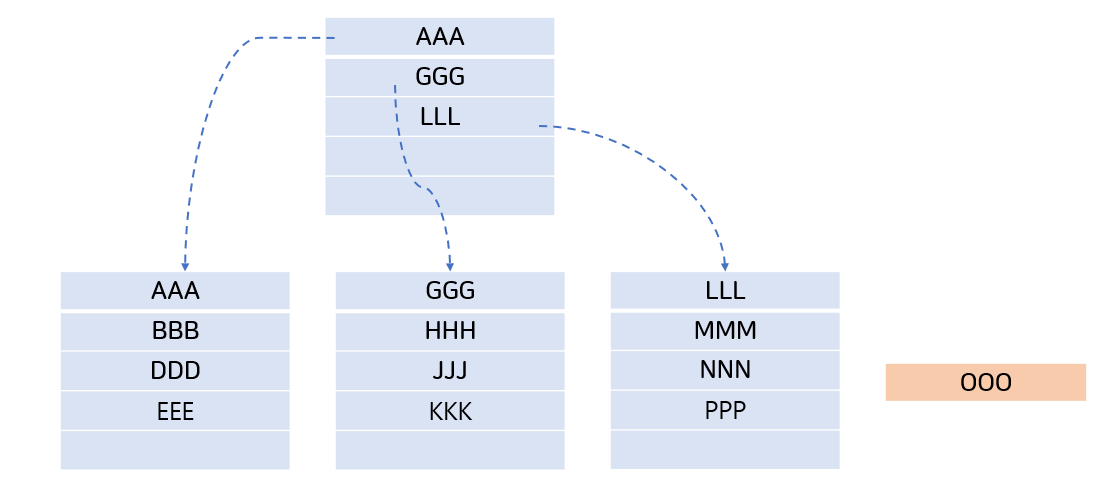
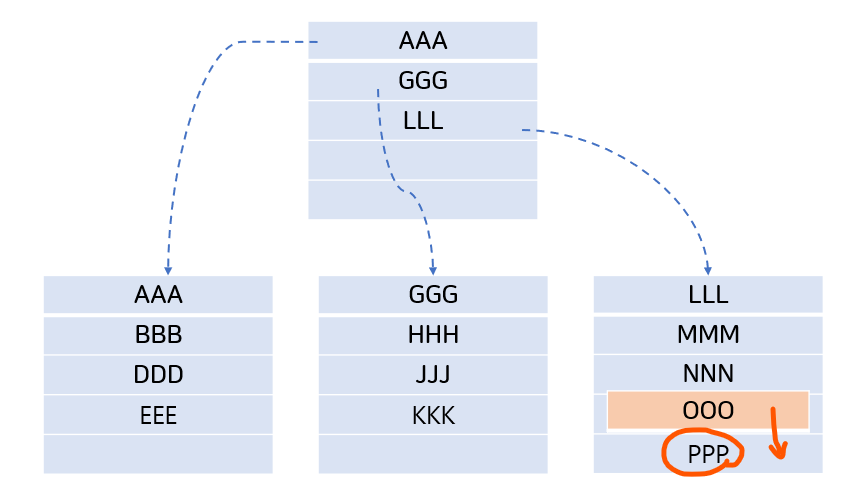
- 밑의 사진처럼 OOO를 넣는다고 가정해보자
![insert1]()
- OOO를 넣기 위해 PPP를 밑으로 옮겨야 할 것이다. 그래도 같은 페이지 내의 이동이라 큰 부담이 없다.
![insert2]()
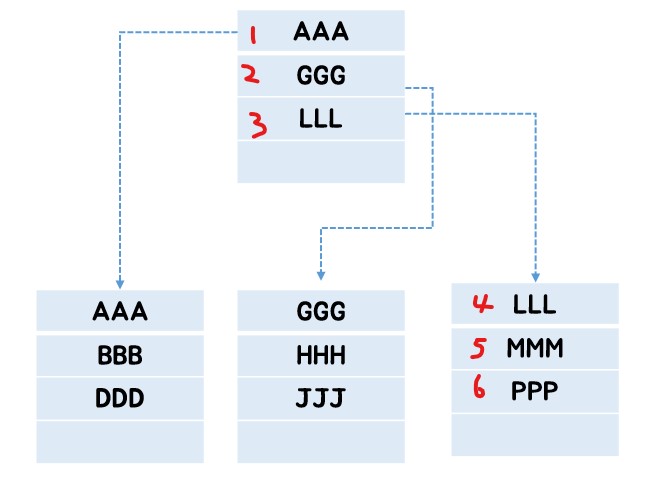
- 그러면 데이터를 넣고 싶은데 해당 페이지가 꽉찼을 땐 어떤 일이 발생할까?
페이지를 새로 생성하고, 꽉 찬 페이지의 데이터를 반으로 나눠갖는 페이지 분할 작업이 발생한다.
이러한 페이지 분할 작업은 DB 성능에 영향을 준다.(느려짐) 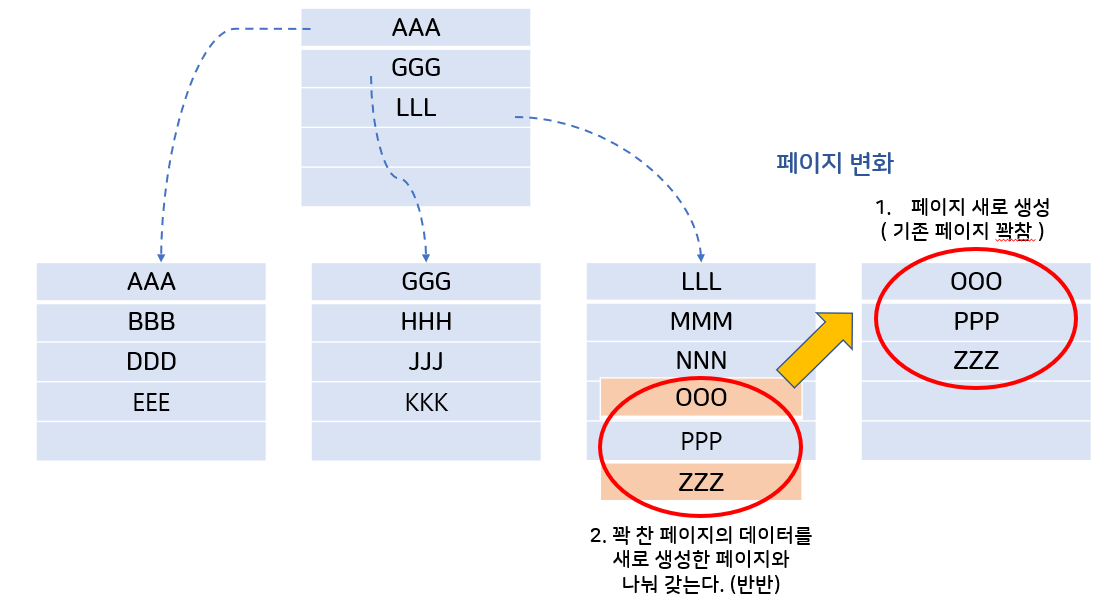
B-Tree의 Delete, Update
- Delete?
인덱스의 데이터를 실제로 지우지 않고 사용안함 표시를 한다. - Update?
인덱스의 데이터를 사용안함 표시를 한 뒤 변경된 값을 삽입한다. - Delete와 Update는 인덱스를 사용하면 where 절로 처리할 대상을 찾는 조회 성능은 개선될것이다.
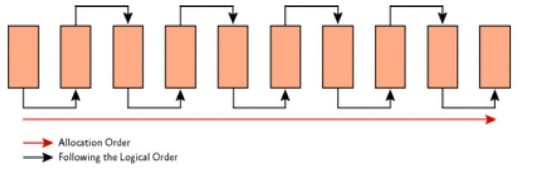
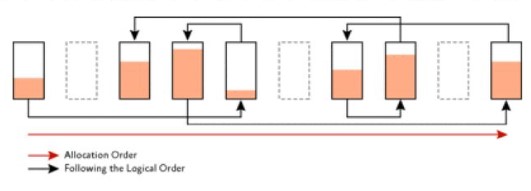
⭐ 다만, 더 이상 사용하지 않을 인덱스라면 불필요한 처리량이 증가하고 사용안함 표시로 페이지 낭비 및 인덱스 조각화가 심해져 성능이 저하된다. - 🤔 인덱스 조각화?
디스크 상에 Page들이 연속적으로 위치해 있지 않고, 공간을 두고 떨어져 있는 현상을 말한다.![non-fragment]()
![fragment]()
어떤 컬럼에 인덱스를 적용해야할까?
인덱스를 지정할 컬럼을 선정할 때 주로 사용하는 방식이 카디널리티이다!
- 카디널리티(Cardinality)가 높은 컬럼
- 카디널리티? 그룹 내 요소의 개수, 중복을 제거한 요소의 개수
- 카디널리티(그룹 내 요소의 개수)가 높은 것. 즉, 중복 수치가 낮은 컬럼에 인덱스를 적용한다.
![Cardinality]()
- WHERE, JOIN, ORDER BY 절에 자주 사용되는 컬럼
- 이유 ? 조건 절이 없다면 인덱스가 사용되지 않기 때문에
- INSERT / UPDATE / DELETE가 자주 발생하지 않는 컬럼
- 성능 저하가 있을 수 있으므로 자주 발생하지 않는 것이 좋다.
- 일반적인 웹 서비스와 같은 온라인 트랜잭션 환경에서 쓰기와 읽기의 비율은 2:8 또는 1:9이다.
따라서 조금 느린 쓰기를 감수하고 빠른 읽기를 선택하는 것도 하나의 방법이다.
- 규모가 작지 않은 테이블